Whether you’re at the doctor’s office, in the classroom, or the mechanic’s, test results aren’t very helpful if you don’t understand the results. It’s the same with monitoring network traffic—the results are here to help you, but knowing how to act on them is just as important.
With over 25 out-of-the-box BACnet diagnostics (and more being added all the time), Optigo Visual Networks has some of the industry’s most powerful OT network observability tools you’ll find. And while we’re always working to help make our tools easier and more intuitive to use, there’s value in sharing a test-by-test walkthrough of what our suite of test results means, and how you can use that information to get your time-to-resolution down to minutes instead of hours or days.
Here, let’s break down each result explaining what’s happening to trigger the alert or warning, and how OptigoVN will direct you to resolve it. For our users, each section will take you to our OptigoVN Knowledge Base where you can find all our diagnostic explanations, helpful FAQs, and how-to guides.
And for those who aren’t using OptigoVN yet (seriously, what are you doing?), this is a great way to see just how deep our BACnet diagnostic tools get to help you resolve issues in your OT network quickly.
Yes, you’re missing out. The good news though, you can sign up for free and get started right this minute.
Jump to Diagnostic:
Busy Router Backpressure
Checksum Errors
Device Global Discovery
Duplicate Device Address
Duplicate Device Instance Number
Duplicate Network Number
Error Messages of Interoperability Type
Error Messages of Operational Type
Error Messages of Programming Type
Error Messages of Unknown Type
Excessive Broadcast by Source
Excessive Change of Value (COV) Rate
Excessive Max Master
Excessive MS/TP Round Trip Token Time
Excessive Number of Devices on a Single MSTP Network
Excessive Read Rate
Excessive Token Hold Time
Excessive TrendLog Buffer Read Rate
Excessive TrendLog Buffer Ready Notification
Excessive Write Rate
Fully Unreachable Devices
Gap in MSTP Device Addressing
Lost Tokens
Number of TrendLog Objects
Partially Unreachable Devices
Router Rejecting Network Messages
Slow Response Time
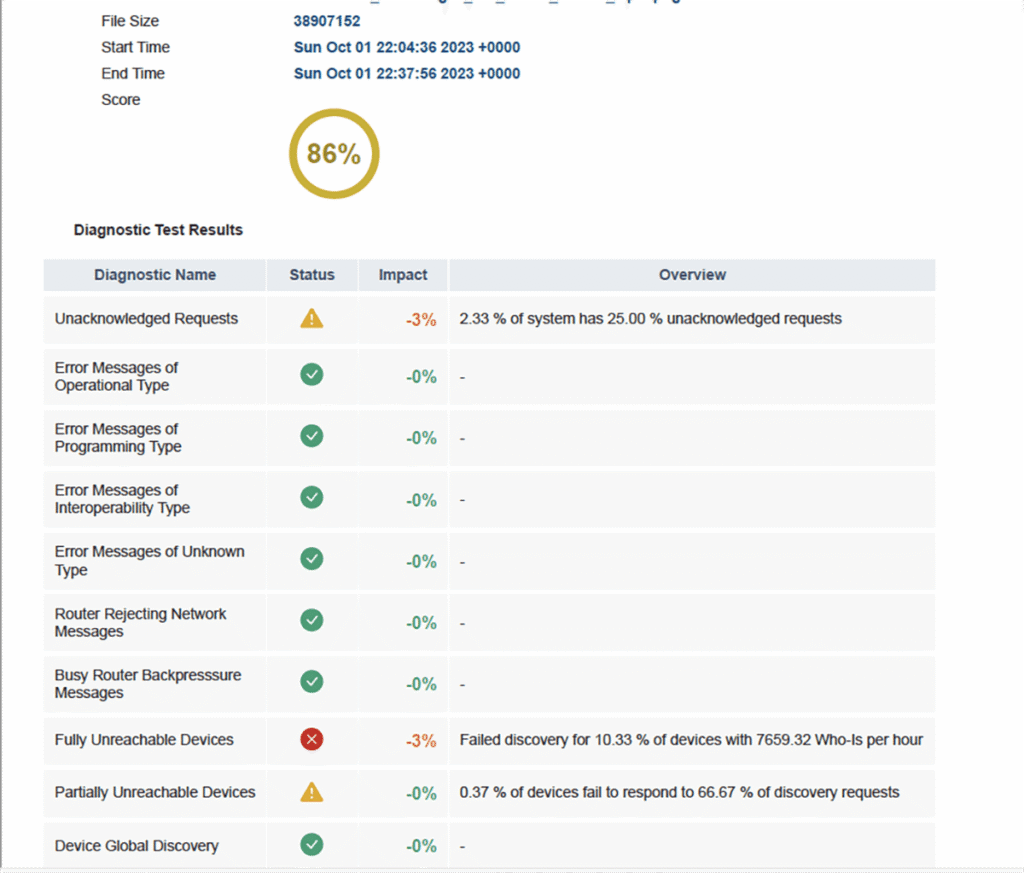
Unacknowledged Requests
Busy Router Backpressure
What Happened?
Your network test returned the “Busy Router Backpressure Messages” warning. This means one or more of your BACnet routers are receiving high levels of traffic and can’t process any more incoming messages.
Overloaded routers can lead to a variety of network issues, including congestion, latency, data loss, and overall performance degradation.
How to Fix It
There are many reasons why router backpressure may be occurring, but most originate from sources creating too much traffic. OptigoVN’s Site Scope results can identify devices that are generating excessive traffic or sending Router-Busy-To-Network messages to help you find areas to optimize your network performance.
Checksum Errors
What Happened?
Your network test returned the “Checksum Errors” message. Checksum errors are commonly the result of physical wiring issues or hardware failures.
Checksum errors typically result in malformed (basically garbled data) and dropped packets.
How to Fix It
Because of the gibberish nature of the data received, you can’t rely on the source addresses in the packet to be correct. We recommend you trace the issue using OptigoVN’s Lost Tokens Diagnostic with an active Site Scope applied to your account. This will help track down devices with wiring or other physical issues.
You can then quickly inspect and fix any faulty wiring terminations for these devices, then repeat your capture to confirm the problem is resolved.
Device Global Discovery
What Happened?
Your network test returned a “Device Global Discovery” error. This means three or more Global Who-Is requests have occurred during the same capture. There are several causes for excessive Global Discovery, including configuration errors, address conflicts, or hardware failure.
These requests trigger a flood of broadcast (I-Am) traffic, leading to communication conflicts and denial-of-service (DoS) issues.
How to Fix It
OptigoVN’s Site Scopes can help to diagnose several of the most common issues to help resolve global discovery issues, including:
- An excessive number of devices on a single MS/TP network
- Duplicate device addresses on the same network
- Device instability causing traffic issues
Duplicate Device Address
What Happened?
Your network test returned a “Duplicate Device Address” error. A simple mistake that can be hard to diagnose, this happens when two devices are assigned the same network address.
Duplication issues can lead to communication conflicts, disruptions, and confusion within the network.
How to Fix It
OptigoVN’s Site Scopes identify the devices with duplicate MAC/IP addresses without having to resort to network bifurcation (splitting your network to see which side the problem persists on). Simply reassign those devices with a new unique MAC or IP address, and retest your network to ensure the issue is resolved.
Duplicate Device Instance Number
What Happened?
Your network test returned a “Duplicate Device Instance Number” error. This means two or more devices on your network have the same BACnet device instance number. This can lead to communication conflicts and disrupt the normal operation of the OT network.
How to Fix It
OptigoVN’s Site Scopes will identify the devices with duplicate BACnet device instances without having to bifurcate your network. Simply reassign those devices with a new unique BACnet instance number, and retest your network to ensure the issue is resolved.
Duplicate Network Number
What Happened?
Your network test returned a “Duplicate Network Number” error. This means two or more routers are directing traffic to the same network segment. This can lead to communication conflicts and disrupt the normal operation of the network.
How to Fix It
OptigoVN’s Site Scopes identify the addresses of all the routers with duplicate network numbers. Simply reassign those devices with a new unique network number, and retest your network to ensure the issue is resolved.
Error Messages of Interoperability Type
What Happened?
Your network test returned an “Error Messages of Interoperability Type” message. This means there are compatibility issues between different devices or components on your network:
- Vendor-specific protocols that are not being understood by other devices.
- Features or capabilities not supported by another device are causing communication errors.
- Differences in BACnet profiles used by devices are leading to communication conflicts.
- Timing variations in device responses trigger communication timeouts or synchronization issues.
How to Fix It
OptigoVN’s Site Scopes will identify the specific devices that are returning interoperability errors in your network for further investigation
However, proactive research and pre-deployment testing are the best ways to prevent interoperability errors:
- When sourcing devices and components, ensure that devices follow BACnet standards and profiles.
- Thoroughly test the interoperability of devices in a controlled environment to identify and address issues.
- Employ consistent configuration profiles, data points, and unit make/model to create consistent and accurate information.
- Verify data mappings and translations between devices to ensure it’s still accurate.
- Keep device firmware up to date to address interoperability-related bugs or issues.
Error Messages of Operational Type
What Happened?
Your network test returned an “Error Messages of Operational Type” message. These issues involve general system faults, and can include a broad number of issues you’ll likely see alongside other specific diagnostic results:
- Device Faults: device malfunctions, hardware failures, or communication problems.
- Communication Errors: failures transmitting or receiving data, indicating potential network communication issues.
- Sensor or Actuator Errors: anomalies or malfunctions in sensors, actuators, or other control devices.
- Network Issues: network congestion, disconnectivity, or instability.
- System Alarm Conditions: predefined alarm conditions, such as temperature thresholds, pressure limits, or security breaches.
- Configuration Errors: incorrect device settings, addressing conflicts, or improper configurations.
- Security Breaches: unauthorized access attempts or security breaches.
- Critical Conditions: potentially critical situations that require immediate attention to prevent system failures or safety risks.
How To Fix It
OptigoVN’s Site Scopes can identify the specific devices that are returning operational errors in your network. However, proactive research and pre-deployment testing are the best ways to prevent interoperability errors:
- Continuously monitor the network and devices for error messages and anomalies.
- Use diagnostic tools and software to identify the root causes of operational errors.
- Regularly perform maintenance, updates, and inspections on devices
- Take appropriate corrective actions quickly, such as reconfiguring devices, replacing faulty components, or addressing security breaches.
Error Messages of Programming Type
What Happened?
Your network test returned an “Error Messages of Programming Type” message. These issues involve general errors in programming, configuration, or logic with your OT network, including:
- Programming Errors: incorrect or faulty logic programming within controllers or devices.
- Data Mapping Errors: incorrect mapping of data points, sensors, or actuators.
- Control Sequence Errors: flawed control sequences, schedules, or sequences of operations.
- Communication Configuration: misconfigured communication settings that hinder proper data exchange between devices.
- Addressing Conflicts: duplicate device addresses or addressing conflicts.
- Program Execution Errors: runtime errors, exceptions, or script failures.
- Alarm and Event Configuration: incorrectly configured alarms, events, or notifications.
How to Fix It
OptigoVN’s diagnostics provide detailed results across several of the categories that fall under this umbrella of errors. OptigoVN’s Site Scopes can then help you drill down to devices that are reporting many of these errors.
We also recommend OptigoVN users upload new PCAP files (or set up continuous monitoring with an Optigo Networks hardware or free software traffic Capture Tool) to confirm improvements to your network health.
There are also several proactive practices to help prevent future programming errors:
- Regularly check your device configs, addressing, and communication settings.
- Test programmed control sequences, logic, and configurations in a controlled environment.
- Use debugging tools, virtual environments, and diagnostic logs to resolve programming errors.
- Make training and knowledge to maintain these best practices part of your onboarding.
Error Messages of Unknown Type
What Happened?
Your network test returned an “Error Messages of an Unknown Type” message. These messages have no specific category or classification. They serve as a generic “something unexpected has occurred” head’s up. Common causes for this message include:
- Undetermined System Behavior: Notifications about unexpected behavior that aren’t easily categorized.
- Ambiguous Faults: Messages indicating a problem that could have multiple potential causes, making it hard to classify.
- Data Corruption: Data corruption or anomalies that don’t fit into a specific error category.
- Unexpected Results: Outcomes or responses that were not anticipated or covered by existing error codes.
- Unrecognized Events: Alerts about events or conditions that the system can’t identify based on its existing error code list.
How to Fix It
OptigoVN’s Site Scopes provide detailed results across several categories that will allow you to drill down to devices that are reporting many of these errors.
We recommend OptigoVN users upload new PCAP files (or set up continuous monitoring with an Optigo Networks hardware or free software traffic Capture Tool) to confirm improvements to your network health.
There are also several root cause analysis practices you can adopt to your troubleshooting processes to help prevent future programming errors:
- Record these error messages for further review.
- Examine the circumstances leading to these messages to try and identify any patterns.
- Look for recurring or similar unknown errors to identify potential commonalities.
- Conduct controlled testing to reproduce the unknown error messages to gather more information.
- Seek assistance from system vendors or experts who might have encountered similar issues.
Excessive Broadcast by Source
What Happened?
The “Excessive Traffic Rate: Broadcast by Source” diagnostic alerts users when the frequency of broadcast packets exceeds the test threshold. The overview will tell you the rate of broadcast packets per minute (PPM), as well as the largest broadcast rate from a single device.

While it’s common to see a lot of broadcast packets in the BACnet protocol, without managing device broadcast frequency, they can become overwhelming to the network as each device must process every broadcast message.
A broadcast flood can have serious implications on overall network performance and stability.
How to Fix It
- Use OptigoVN Site Scope(s) to identify the MAC/IP addresses of all devices transmitting a high rate of broadcast messages. Adjust the configurations of devices to lower the frequency of broadcast messages, and retest to ensure the issue has been resolved.
- Network routing: Consider whether devices with high broadcast need to be in contact with all other devices in your network. If possible, create routing limiting the number of devices the broadcast will reach.
The next few error messages are closely related as they all reference devices sending a lot of traffic in a very short period. While the explanations might differ, the causes and solutions are usually the same.
Excessive Change of Value (COV) Rate
What Happened?
Your network test returned an “Excessive Change of Value (COV) Rate” message. This means that the average gap between COV messages coming from one or more of your network devices is very small, and it’s producing a lot of data on the network. Our threshold for alerting is more than one COV message per device every five minutes.
Excessive COV rates can negatively affect the performance of your network, leading to an increase in response times, decreased resources, and instabilities across your system.
How to Fix It
It’s important to note that high COV rates aren’t always a bad thing. There are situations where precise data, and therefore a lot of reporting, is a requirement. That said, excessive COV rates are often the result of programmers creating blanket polling policies for all object types across all devices. In a large system, this has the potential to trigger a flood of unnecessary data traffic.
OptigoVN’s Site Scopes can identify the addresses of devices causing COVs above our set threshold, allowing you to deep dive into packets to understand read properties (here’s our BACnet Object Glossary to identify the points being read), and tune the number of reads per device to your needs. This can help reduce needless traffic and congestion across your network.
Some common ways of tuning we recommend include:
- Configuration Review: Review and verify configuration settings for data polling rates to ensure they align with the intended requirements.
- Reduce Poll Rates: Set appropriate polling frequencies based on the importance of the data, the rate of change, and the system’s operational needs.
- Optimize Control Programming: Optimize control programs and scripts to avoid unnecessary or redundant data polling.
- Continuous Network Monitoring: Monitor network traffic and resource usage to identify patterns of excessive read rates.
Excessive Max Master
What Happened?
Your network test returned the “Excessive Max Master” message. This means the max master setting on your MS/TP network exceeds the last master device by more than two – for example, you have 20 devices on your network but the max_master value is set to 23 or higher. The usual cause for this is that the factory default setting of 127 was never modified.
An incorrect max master setting will cause unnecessary poll-for-master calls, slowing down communications on the network.
How to Fix It
Configure your max_master value on the device to be no more than two above the last master device on the network.
Excessive MS/TP Round Trip Token Time
What Happened?
Your network test returned the “Excessive MSTP Round Trip Token Time” message. This means the average token trip time around the network is longer than two seconds. The optimal round-trip time is 85ms or less.
This issue is often wiring-related, and the latency leads to communication conflicts and lost messages.
How to Fix It
OptigoVN’s Site Scopes results can identify devices with excessive round-trip times. You’ll have to physically inspect and fix any faulty wiring terminations at these devices, then repeat your capture to confirm the problem is resolved.
Excessive Number of Devices on a Single MSTP Network
What Happened?
Your network test returned the “Excessive Number of Devices on Single MSTP Network” error. This means OptigoVN has detected more than 32 master devices on an MS/TP network – which typically leads to a loss of speed and integrity.
While an MS/TP network can officially accommodate 127 devices on a single network, it’s generally accepted that more than 32 impacts performance significantly.
How to Fix It
To resolve this, we recommend breaking up larger MS/TP networks into two or more smaller segments using BACnet routers.
Excessive Read Rate
What Happened?
Your network test returned an “Excessive Read Rate” message. This means that the average gap between reads on one or more of your network devices is very small, and it’s producing a lot of data on the network. Our threshold for alerting is more than one read per device every five minutes.
Excessive read rates can negatively affect the performance of your network, leading to an increase in response times, decreased resources, and instabilities across your system.
How to Fix It
Like COV warnings, high read rates aren’t always bad, but we want you to be aware they’re happening (in case you aren’t). Excessive read rates are often the result of programmers creating blanket polling policies for all object types across all devices. In a large system, this has the potential to trigger a flood of unnecessary data traffic.
OptigoVN’s Site Scopes can identify the addresses of devices causing reads above our set threshold, allowing you to deep dive into packets to understand read properties (here’s our BACnet Object Glossary to identify the points being read), and tune the number of reads per device to your needs. This can help reduce needless traffic and congestion across your network.
Some common ways to consider tuning include:
- Configuration Review: Review and verify configuration settings for data polling rates to ensure they align with the intended requirements.
- Reduce Poll Rates: Set appropriate polling frequencies based on the importance of the data, the rate of change, and the system’s operational needs.
- Optimize Control Programming: Optimize control programs and scripts to avoid unnecessary or redundant data polling.
- Convert Reads into Change-of-Value: Instead of polling the value, use a Change-of-Value “push” notification when the value changes.
- Continuous Network Monitoring: Monitor network traffic and resource usage to identify patterns of excessive read rates.
Excessive Token Hold Time
What Happened?
Your network test returned the “Excessive Token Hold Time” error. This means OptigoVN has detected a device on your network holding the MS/TP token for longer than 500ms. This suggests that an MS/TP device on your network is trying to communicate too many messages, possibly running out of time to finish before the token moves along.
The result can be network congestion and delayed messages.
How to Fix It
OptigoVN’s Site Scopes will identify devices with excessive token hold times. In the device configuration, you can increase the max_info_frame device attribute (default is 1) to flush out the buffer and/or reduce the amount of messages being sent.
Excessive TrendLog Buffer Read Rate
What Happened?
Your network test returned the “Excessive TrendLog Buffer Read Rate” diagnostic alert. This alert is to let you know OptigoVN has detected a frequency of read requests to a TrendLog buffer that exceeds our threshold of once every 10 minutes.
While some rapid reads are normal from time to time, a consistently high read rate can be an indication of configuration or programming issues.
Excessive read rates generate a high volume of network traffic, affecting network performance, response times, and affecting overall system stability.
How to Fix it:
OptigoVN Site Scopes can identify the MAC/IP addresses of all devices with excessive TrendLog buffer read rates. Follow-up steps include:
- Configuration Review: Review and verify configuration settings for the TrendLog object highlighted in the diagnostic event. Ensure that the threshold and buffer size are set to appropriate levels to avoid filling up the buffer too quickly. Retest to ensure the issue has been resolved.
- Testing: Conduct testing to ensure that the system’s read rates are within acceptable limits and that data is collected efficiently.
Excessive TrendLog Buffer Ready Notification
What Happened?
The “Excessive TrendLog Buffer Ready Notification” is an alert to let you know when a TrendLog buffer is being filled more than once every 10 minutes.
While TrendLog notifications are a normal process, you should be aware when the notifications for the same Trendlog object are high—it can be a sign of configuration or programming issues.
Excessive read rates generate a high volume of network traffic, affecting network performance, response times, and affecting overall system stability.
How to Fix It:
- OptigoVN Site Scopes can identify the MAC/IP addresses of the device with buffer full notifications higher than our set threshold. Adjust the configurations of devices to lower the frequency of TrendLog buffering, and retest to ensure the issue has been resolved.
- Configuration Review: Review and verify configuration settings for the TrendLog object highlighted in the diagnostic event. Make sure that the threshold and buffer size are set to appropriate levels to avoid filling up the buffer too quickly.
- Testing: Conduct testing to ensure that the system’s read rates are within acceptable limits and that data is collected efficiently.
Excessive Write Rate
What Happened?
Your network test returned an “Excessive Write Rate” message. This means that your Building Automation Systems (BAS) is performing write operations (updating data or settings) to a device at an unusually high frequency. There are a few common causes for this, including:
- Incorrectly configured settings
- Malfunctioning or inefficient control programming
- Frequent adjustments to control loops
- Excessive data logging
Excessive write operations can generate high levels of network traffic, impacting network performance, and contributing to increased wear and reduced device lifespan.
How to Fix It
Write rates should be tuned specifically to your needs, and this diagnostic result doesn’t always mean there is a problem, it’s more of a head’s up — in the event you want to optimize your settings.
OptigoVN’s Site Scopes can identify all devices with excessive write rates above our set threshold, allowing you to deep dive into the results (here’s our BACnet Object Glossary to identify the points being written) and tune writes per device to your needs.
Some common ways of tuning we recommend include:
- Configuration Review: Review and verify configuration settings for data polling rates to ensure they align with the intended requirements.
- Write Frequency Guidelines: Set write frequencies based on the frequency of control changes, data logging requirements, and system performance goals.
- Optimize Control Programming: Optimize control programs and scripts to avoid unnecessary or redundant data polling.
- Control Loop Tuning: Tune control loops to prevent rapid and unnecessary adjustments that lead to excessive write operations.
- Data Logging Strategies: Implement efficient data logging strategies to minimize unnecessary write operations for logging.
- Continuous Network Monitoring: Monitor network traffic and resource usage to identify patterns of excessive write rates.
- Testing: Conduct regular testing to ensure that the system’s write rates align with operational requirements and don’t negatively impact device performance.
Fully Unreachable Devices
What Happened?
Your network test returned a “Fully Unreachable Devices” error. This means one or more devices on your network aren’t responding to any of the Who-Is requests sent with an I-Am response during the capture. Unlike a partially unreachable device, these are completely unavailable all the time.
There are several common causes for unreachable devices, like power failures, physical disconnects, device failures, programming or configuration errors, and security/firewall settings.
How to Fix It
OptigoVN’s Site Scopes will identify all non-responding devices on the network. Once identified, you’ve got a few actions available to resolve the issue, including:
- Reviewing device and network configurations for errors or mismatches.
- Resetting the querying device to clear its cache and force it to reestablish connections.
- Modify the programming of the querying devices to stop searching for a removed device, and reset its cache to reestablish its connections.
- Physically inspect unreachable devices and network infrastructure for damaged cables or components, and confirm it’s still present.
- Adjust firewall and security settings to allow necessary communication for BACnet devices.
- Review your network topology to ensure devices are in the correct segments and routing is configured properly.
Gap in MSTP Device Addressing
What Happened?
Your network test returned the “Gap in MSTP Device Addressing” error. This means OptigoVN has detected that devices are not addressed sequentially within your network.
This can lead to communication delays as devices take time to repeatedly look for (poll-for-master) those missing MAC addresses every 50 token cycles.
How to Fix It
OptigoVN’s Site Scopes will identify exactly which addresses are missing in the sequence, so you can quickly re-configure device addresses to fill any gaps.
Lost Tokens
What Happened?
Your network test returned the “Lost Tokens” error. This means OptigoVN has detected a Reply-To-Poll-For-Master (RTPFM) message on your network. While this can sometimes result from adding a new device while capturing packet data, it’s most likely a physical wiring issue somewhere on the network.
Lost Tokens will result in communication loss between devices, and dropped packets.
How to Fix It
OptigoVN’s Site Scopes will quickly identify the source and destination devices with lost tokens. You’ll have to physically inspect and fix any faulty wiring issues, then repeat your capture to confirm the problem is resolved.
Number of TrendLog Objects
What Happened?
It can be difficult to know how many processes might be running in the background within a BACnet system. The “Number of TrendLog Objects” diagnostic is informational only— designed to quickly let you know what devices on your network currently have TrendLogs active. Removing unnecessary Trendlog objects will reduce memory and storage resources.
More information:
- This diagnostic will identify the total number of active TrendLogs on your network and highlight the object with the highest number of active TrendLogs.
- An active TrendLog is defined as a TrendLog object that has sent at least one BUFFER_READY notification.
- The maximum number of TrendLogs per device is 50.
Partially Unreachable Devices
What Happened?
Your network test returned a “Partially Unreachable Devices” error. This means one or more devices on your network have not responded to at least one of the Who-Is requests with an I-Am response during the capture. Unlike fully unreachable devices, partially unreachable devices respond sporadically—or may fail to respond to certain requests completely.
There can be several reasons devices become partially unreachable, including network congestion and geographic latency, power fluctuations, software issues, and device overload.
How to Fix It
OptigoVN’s Site Scopes will identify all partially responding devices on the network. Once identified, you’ve got a few actions available to resolve the issue, including:
- Physically inspecting devices and network infrastructure for issues like damaged cables or components.
- Monitoring network/subnet traffic levels and quality to identify congested segments or areas with signal interference.
- Assessing device load and distributing tasks efficiently to prevent overload.
- Checking—and then keeping—device firmware and software up to date.
- Ensuring stable power to devices to prevent voltage fluctuations that can affect communication.
- Optimize routing or network topology to reduce latency.
Router Rejecting Network Messages
What Happened?
Your network test returned a “Router Rejecting Network Messages” error. This means that a router on your network isn’t forwarding or passing on certain messages, data packets, or communication requests. This can be caused by misconfigured policies, resource overload, network congestion, and security settings.
These types of errors can lead to data loss, communication breakdown, operational errors, congestion, and stability issues.
How to Fix It
OptigoVN’s Site Scopes can identify how many, and how often, routers are rejecting network messages. You can then take several actions to resolve the issue, including:
- Verifying the router’s access control policies and configuration settings.
- Reviewing security settings to prevent false positives while still blocking potential threats.
- Monitoring the router performance and utilization levels.
- Conducting testing and simulations to reproduce rejected messages to identify root causes.
- Keeping router software and firmware up to date.
Slow Response Time
What Happened?
Your network test returned a “Slow Response Time” message. This means a device on your network is taking longer than our recommended time (in seconds) between a Who-Is request and the I-Am response.
Network congestion is often the culprit behind slow response times, with either the responding device being overloaded, too many network hops, or the destination device experiencing latency. Slow response times can have impacts ranging from annoying – delays in receiving messages – to an inability to monitor critical or sensitive systems in an acceptable time frame.
How to Fix It
By using OptigoVN’s Site Scope’s detailed diagnostic results, you can identify the path between the requesting and responding device for each slow response time. You can then investigate the routers in the path to see the level of traffic passing between them. You can also check the responding devices to see if they are also experiencing congestion.
Don’t forget, after optimizing your network for traffic flow, retest your network to ensure the issues are resolved.
Unacknowledged Requests
What Happened?
Your network test returned a “Unacknowledged Requests” error message. This is to let you know there is one or more devices on your network that did not receive an acknowledgment after sending a message.
This error typically occurs when the destination device (or its router) is either offline or busy. Unacknowledged requests can lead to data loss, fault detection delay, and overall degradation of system performance.
How to Fix It
OptigoVN’s Site Scope’s detailed diagnostic results will identify which device has failed to respond, allowing you to quickly focus on resolving the issue. Inspecting the hardware for any physical issues, such as lost or damaged cables, as well as confirming proper configuration, is a good first step.
Addressing unacknowledged requests requires a combination of troubleshooting, network optimization, and careful configuration:
- Identify patterns of unacknowledged requests to pinpoint specific devices or areas in the network that are experiencing communication issues.
- Adjust retransmission parameters on devices to allow for a reasonable number of retries without overwhelming the network with unnecessary traffic.
- Review the network topology to ensure that there are no physical barriers or interference causing communication problems.
- Minimize the amount of unnecessary traffic on the network by optimizing communication patterns and avoiding excessive polling.
- Ensure that devices’ clocks are synchronized to prevent timing issues that might lead to unacknowledged requests.
- Implement Quality of Service (QoS) mechanisms to prioritize critical messages and prevent them from being lost due to network congestion.
- Keep devices’ firmware up to date.
- Consider segmenting the network into smaller sub-networks to reduce network congestion and improve reliability.
- Regularly test devices’ communication and monitor network traffic to identify and address unacknowledged requests promptly.
Make Bad OT Network Health Scores History
OptigoVN’s got an answer for just about every BACnet issue you might encounter, and we’re adding more all the time!
If you’re a systems integrator, you already know your time is your money. These kinds of deep network insights can easily save hours on a call, enabling you to service more clients on your roster and scale your business faster than ever. It also prevents return visits and multiple truck rolls. Imagine being aware of what the issue and resolution are before you leave your office.
But that’s only half the story. By moving from a routine where you wait for something to go wrong, or only check in on your OT system once or twice a year, to one where regular monitoring and preventative maintenance are part of your program, you become a strategic partner. Now, you’re driving long-term value and reducing risk for your clients over time, AND reducing your client churn!
This is where the adoption of cloud-based BACnet systems monitoring software can set Systems Integrators up for success. That’s what working with OptigoVN can do for you.
Want to see it in action? Learn more and sign up for a free at www.optigo.net/optigovn


