
Unreachable OT devices can cause a lot of unnecessary traffic and confusion on an Operational Technology (OT) network, and it can be difficult to pin down exactly what might be the root cause of the issue. Depending on your network’s configuration, it could be stuck in a loop trying to establish a connection with a device that won’t ever answer.
And from a troubleshooting perspective, “no answer” isn’t much of an answer at all.
Traditionally, the only way to solve an issue like unreachable devices would involve physical inspections, multimeters, and line-by-line config file review. Today, we can leverage powerful diagnostic tools like OptigoVN to greatly narrow down the cause, the devices involved, and the solution that might save you time up a ladder!
Fully vs. Partially Unreachable OT Devices
One of the more frustrating things about diagnosing unreachable devices is that it isn’t always strictly a working/not working situation. It’s possible to have devices that are online one moment and then gone the next. And that can be your first clue when it comes to tracking down the cause.
Heads up: These are the diagnostic terms that we use in OptigoVN to flag these issues. Other platforms may use slightly different terms, such as “unresponsive”, but the symptoms and situations are the same.
Fully Unreachable Devices
As the name suggests, a fully unreachable device isn’t picking up the phone for anyone. It’s a device that won’t respond to requests or messages other devices are sending, such as WHO-IS.
In this basic example below, a source (represented by the computer) is sending a WHO-IS message to a BACnet controller device with the ID 249, because its configuration tells it there’s supposed to be a device there. This device is unreachable, though, so no I-AM acknowledgment message is returning.
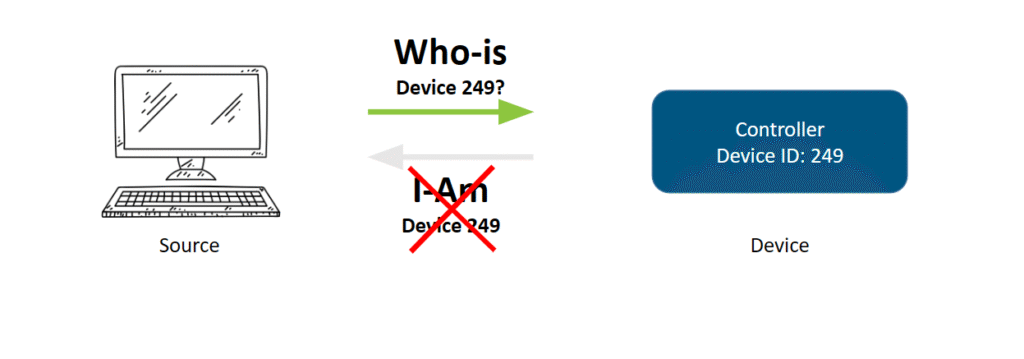
Depending on your configuration, the source might continue to send out Who-Is requests for device 249 until it gets a reply. That could be in perpetuity if you don’t fix the unreachable device. Among other things, this ties up system resources, bogs down networks with unnecessary traffic, and can even prevent commands from being executed.
Partially Unreachable Devices
The other possibility is a device that responds, but only sometimes, which can be even more confusing to your BAS than one that simply fails to appear at all. Specifically, OptigoVN will flag a partially unreachable issue if one or more devices on your network have not responded to at least one of the Who-Is requests with an I-Am response. Partially unreachable devices may respond to some requests but not others, or they may respond intermittently.
Why Distinguish the Two?
After all, from an operational perspective, the outcome is the same—at some point communication is going to break down, so who cares? Data is going to be delayed or corrupted resulting in real-world failures to respond, or critical errors that might bring the whole system down.
The reason to distinguish is because the causes for unreachable devices directly affect the path to a solution.
Let’s look at the three most common scenarios—Phantom Devices, Failed Devices, and Path Failure—that can lead to unreachable devices on a BACnet OT network, and how those scenarios point to their possible causes. Then, let’s look at how OptigoVN can help you drive straight to the device in question, and make resolution much faster.
1. Phantom Devices
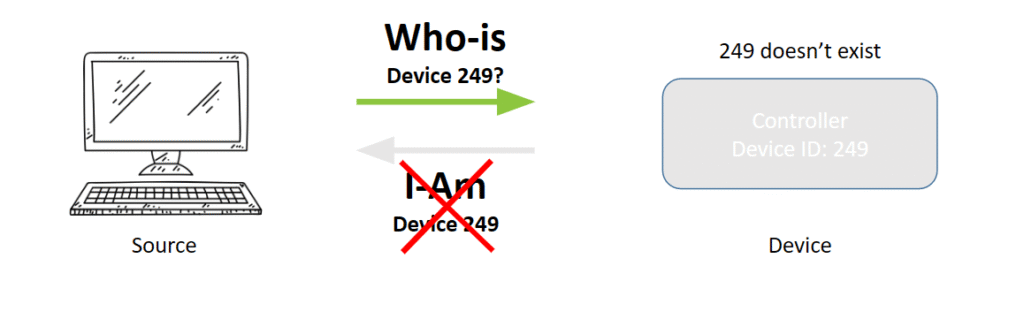
In the scenario above, the first question you need to ask is, “Should device 249 even be on the network?” Sometimes the answer is a simple no. If you know for sure that device isn’t on the network, you have what’s referred to as a Phantom Device, and it’s one of the leading causes of fully unreachable devices. In this scenario, the problem is actually with the source device, which for some reason thinks it needs to find device 249.
Devices may be regularly added or removed from your OT network over time for a variety of reasons, especially if you’re working with a large OT network serviced by multiple vendors (making this another strong argument for keeping an up-to-date asset inventory!). As we all know, BACnet devices need to be manually updated anytime something changes, so simple human error like this becomes an extremely common issue, particularly in MS/TP networks.
There are a few things you can look at to troubleshoot this:
- Is the source device programmed to look for device 249? You’ll want to review your configuration files and update if necessary.
- Is the source device receiving a message from another device that it’s supposed to route to 249? You might need to perform a packet capture from another location on your network to pinpoint that issue.
2. Failed Devices
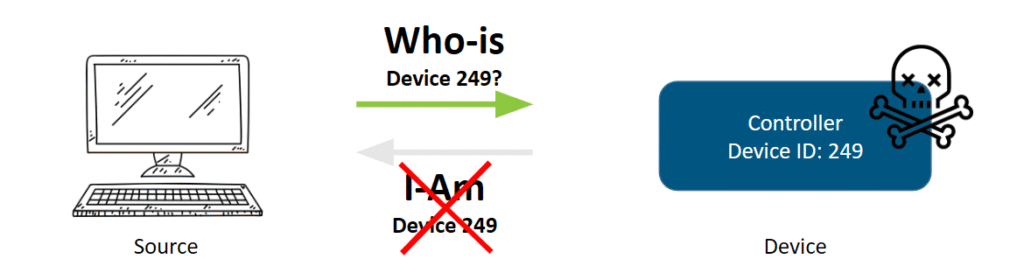
If you know that device 249 should be on the network, and should be responding to WHO-IS requests, you might have a failed device. This is a common issue that a lot of people have dealt with, and there are many potential causes. In this case, you want to troubleshoot the device itself. It could be a physical issue (maybe the device no longer has power), or a misconfiguration.
A failed device doesn’t necessarily mean it’s a dead device, since it could be a wiring or performance issue, but it would explain why they may show up as both partially and fully unreachable—depending on the length of your diagnostic capture session. Here’s a quick list of things to look out for:
- Physically inspect unreachable devices and network infrastructure for damaged cables or components.
- Ensure the device has stable power to prevent voltage fluctuations that can affect communication.
- On older network devices, you may need to confirm proper configuration, like baud and power rates, through physical dip switches on the device itself.
3. Path Failure
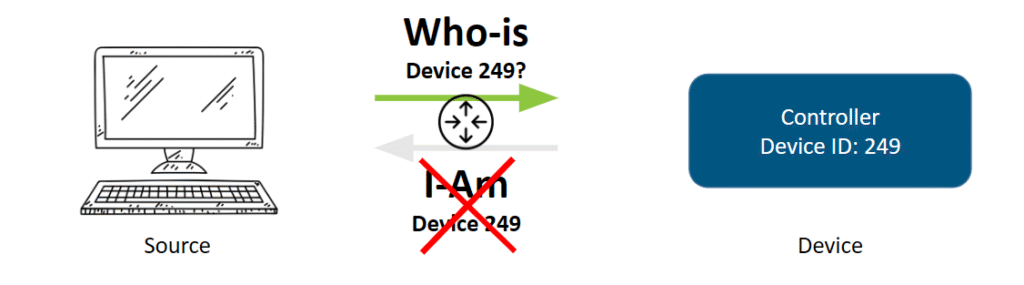
Finally, you could be dealing with a path failure, in that the route the data is traveling along the network between the source and the destination is the issue. This can be more complicated to diagnose but is also a common cause of partially unreachable devices. That said, we recommend that you eliminate the first two possibilities first.
Using our example, we need to apply a bit of real-world networking to it. Based on how BACnet networks are often designed, the WHO-IS message request from the source rarely goes directly to a destination device. It’s likely being routed through a few different devices to get there—via a router, a gateway, or a series of different BACnet devices.
If you’ve determined that the source and the destination device are both working as they should be, you’ll have to troubleshoot the path that’s connecting them. This is where it’s vital to have an up-to-date (ideally automated) network topology map, so you can identify if there’s a common thread — like a router, or wiring — to the devices that are struggling to communicate, or other offline devices within the same segment.
Troubleshooting the path is time-consuming, but doesn’t have to be challenging with the right tools. And if you resolve what’s broken in the path then you might also fix several other devices that are struggling to communicate. Win-win.
Bonus Tip: Too Many Sources
Another way to identify the cause of an unreachable device is to look at the number of source devices that aren’t able to communicate with a specific device. If a device is being sent messages from many different sources, it’s quite likely that you’ve programmed all these source devices correctly, and you have a device on the other end that’s failed.
On the flip side, if you have just one querying device, it’s more likely that there was a misconfiguration on the source device.
Did you know? OptigoVN’s unreachable device table can be sorted to identify all of the devices querying a controller found to be unreachable!
Using OptigoVN to Fix Unreachable Devices
In theory, decoding unreachable devices is simple: something, somewhere, is getting lost in translation. But when the device isn’t communicating on the network, you might not even know it’s supposed to be there.
These situations are where troubleshooting solutions like OptigoVN are going to be a big help. Firstly, OptigoVN’s powerful suite of diagnostics includes specific tests for partially and completely unreachable devices. Right off the bat, you’re already zeroing on possible issues, rather than running the gamut of manual tests to arrive at the same place, hours later.
OptigoVN’s Site Scope and Site Scope+ add-ons will identify all non-responding devices on the network. Once identified, you’ve got a few actions available to resolve the issue, including:
- Physically inspecting devices and network infrastructure for issues like loose and damaged cables or components.
- Reviewing device and network configurations for errors or mismatches.
- Resetting the querying device to clear its cache and force it to reestablish connections.
- Modifying the programming of the querying devices to stop searching for a removed device, and reset its cache to reestablish its connections.
- Physically inspecting unreachable devices and network infrastructure for damaged cables or components.
- Adjust firewall and security settings to allow necessary communication for BACnet devices.
Secondly, tricky diagnoses like path failure are going to be much easier to identify because OptigoVN will surface other network communication issues from different failures that will help you identify the root cause. For example, too much traffic can easily overwhelm older MS/TP devices, leading to intermittent connectivity issues. Diagnostic flags from OptigoVN, like round-trip token time, lost tokens, and even excessive COV rates are all results that can help you determine where to start.
Most powerful, though, is the ability to get directly to the device level right from your computer with OptigoVN. Not only do you get device-level confirmation of issues (like unavailability), but contextual results (like how long or how many messages haven’t been responded to) that help you quickly get from identifying an issue to resolving it faster than ever before.
Like fully unreachable devices, OptigoVN will identify all partially responding devices on the network. Once identified, you’ve got a few additional things to consider, including:
- Monitoring network/subnet traffic levels and quality to identify congested segments.
- Assessing device load and distributing tasks efficiently to prevent overload.
- Keeping device firmware and software up-to-date.
- Ensuring stable power to devices to prevent voltage fluctuations that can affect communication.
- Optimize routing or network topology to reduce latency.
Want to see what OptigoVN can fix for you? There’s never been a better time to start with the industry’s most powerful OT network diagnostic tool. Sign up for free today or contact us to schedule a personalized demo and see how our platform can empower your team.


